Last updated: May 2021
Table Of Contents
- Introduction
- How was it done before?
- How to use
3.1 Interlude: PerformanceTimeline
3.2 ResourceTiming
3.3 Initiator Types
3.4 What Resources are Included
3.5 Crawling IFRAMEs
3.6 Cached Resources
3.7 304 Not Modified
3.8 The ResourceTiming Buffer
3.9 Timing-Allow-Origin
3.10 Blocking Time
3.11 Content Sizes
3.12 Service Workers
3.13 Compressing ResourceTiming Data
3.14 PerformanceObserver - Use Cases
4.1 DIY and Open-Source
4.2 Commercial Solutions - Availability
- Tips
- Browser Bugs
- Conclusion
- Updates
1. Introduction
ResourceTiming is a specification developed by the W3C Web Performance working group, with the goal of exposing accurate performance metrics about all of the resources downloaded during the page load experience, such as images, CSS and JavaScript.
ResourceTiming builds on top of the concepts of NavigationTiming and provides many of the same measurements, such as the timings of each resource’s DNS, TCP, request and response phases, along with the final "loaded" timestamp.
ResourceTiming takes its inspiration from resource Waterfalls. If you’ve ever looked at the Networking tab in Internet Explorer, Chrome or Firefox developer tools, you’ve seen a Waterfall before. A Waterfall shows all of the resources fetched from the network in a timeline, so you can quickly visualize any issues. Here’s an example from the Chrome Developer Tools:
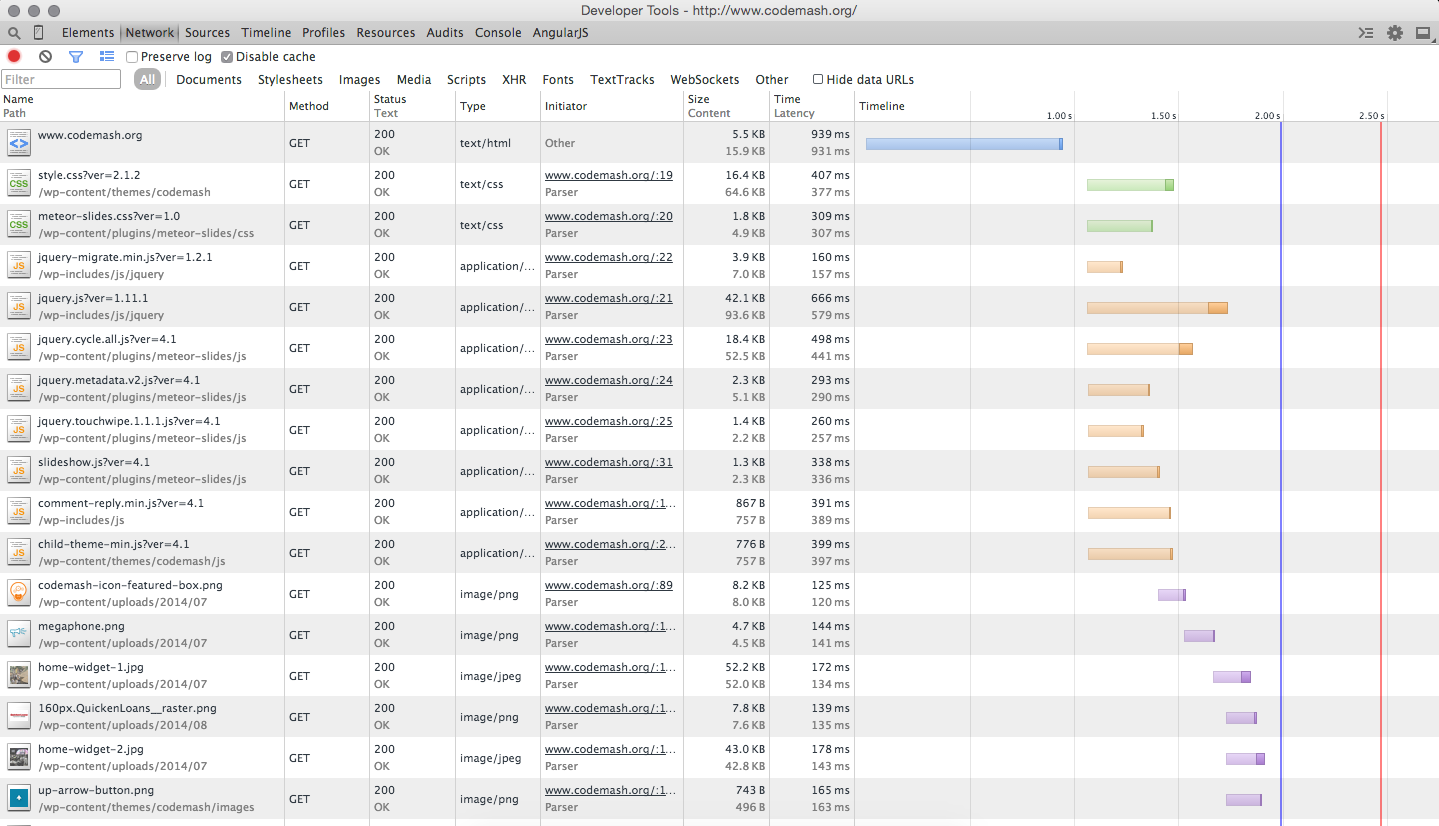

ResourceTiming (Level 1) is a Candidate Recommendation, which means it has been shipped in major browsers. ResourceTiming (Level 2) is a Working Draft and adds additional features like content sizes and new attributes. It is still a work-in-progress, but many browsers already support it.
As of May 2021, 96.7% of the world-wide browser market-share supports ResourceTiming.
How was it done before?
Prior to ResourceTiming, you could measure the time it took to download resources on your page by hooking into the associated element’s onload event, such as for Images.
Take this example code:
var start = new Date().getTime();
var image1 = new Image();
image1.onload = function() {
var now = new Date().getTime();
var latency = now - start;
alert("End to end resource fetch: " + latency);
};
image1.src = 'http://foo.com/image.png';With the code above, the image is inserted into the DOM when the script runs, at which point it sets the start variable to the current time. The image’s onload event calculates how long it took for the resource to be fetched.
While this is one method for measuring the download time of an image, it’s not very practical.
First of all, it only measures the end-to-end download time, plus any overhead required for the browser to fire the onload callback. For images, this could also include the time it takes to parse and render the image. You cannot get a breakdown of DNS, TCP, SSL, request or response times with this method.
Another issue is with the use of Date.getTime(), which has some major drawbacks. See our discussion on DOMHighResTimeStamp in the NavigationTiming discussion for more details.
Most importantly, to use this method you have to construct your entire web app dynamically, at runtime. Dynamically adding all of the elements that would trigger resource fetches in <script> tags is not practical, nor performant. You would have to insert all <img>, <link rel="stylesheet">, and <script> tags to instrument everything. Doing this via JavaScript is not performant, and the browser cannot pre-fetch resources that would have otherwise been in the HTML.
Finally, it’s impossible to measure all resources that are fetched by the browser using this method. For example, it’s not possible to hook into stylesheets or fonts defined via @import or @font-face statements.
ResourceTiming addresses all of these problems.
How to use
ResourceTiming data is available via several methods on the window.performance interface:
window.performance.getEntries();
window.performance.getEntriesByType(type);
window.performance.getEntriesByName(name, type);Each of these functions returns a list of PerformanceEntrys. getEntries() will return a list of all entries in the PerformanceTimeline (see below), while if you use getEntriesByType("resource") or getEntriesByName("foo", "resource"), you can limit your query to just entries of the type PerformanceResourceTiming, which inherits from PerformanceEntry.
That may sound confusing, but when you look at the array of ResourceTiming objects, they’ll simply have a combination of the attributes below. Here’s the WebIDL (definition) of a PerformanceEntry:
interface PerformanceEntry {
readonly attribute DOMString name;
readonly attribute DOMString entryType;
readonly attribute DOMHighResTimeStamp startTime;
readonly attribute DOMHighResTimeStamp duration;
};Each PerformanceResourceTiming is a PerformanceEntry, so has the above attributes, as well as the attributes below:
[Exposed=(Window,Worker)]
interface PerformanceResourceTiming : PerformanceEntry {
readonly attribute DOMString initiatorType;
readonly attribute DOMString nextHopProtocol;
readonly attribute DOMHighResTimeStamp workerStart;
readonly attribute DOMHighResTimeStamp redirectStart;
readonly attribute DOMHighResTimeStamp redirectEnd;
readonly attribute DOMHighResTimeStamp fetchStart;
readonly attribute DOMHighResTimeStamp domainLookupStart;
readonly attribute DOMHighResTimeStamp domainLookupEnd;
readonly attribute DOMHighResTimeStamp connectStart;
readonly attribute DOMHighResTimeStamp connectEnd;
readonly attribute DOMHighResTimeStamp secureConnectionStart;
readonly attribute DOMHighResTimeStamp requestStart;
readonly attribute DOMHighResTimeStamp responseStart;
readonly attribute DOMHighResTimeStamp responseEnd;
readonly attribute unsigned long long transferSize;
readonly attribute unsigned long long encodedBodySize;
readonly attribute unsigned long long decodedBodySize;
serializer = {inherit, attribute};
};Interlude: PerformanceTimeline
The PerformanceTimeline is a critical part of ResourceTiming, and one interface that you can use to fetch ResourceTiming data, as well as other performance information, such as UserTiming data. See also the section on the PerformanceObserver for another way of consuming ResourceTiming data.
The methods getEntries(), getEntriesByType() and getEntriesByName() that you saw above are the primary interfaces of the PerformanceTimeline. The idea is to expose all browser performance information via a standard interface.
All browsers that support ResourceTiming (or UserTiming) will also support the PerformanceTimeline.
Here are the primary methods:
getEntries(): Gets all entries in the timelinegetEntriesByType(type): Gets all entries of the specified type (egresource,mark,measure)getEntriesByName(name, type): Gets all entries with the specified name (eg URL or mark name).typeis optional, and will filter the list to that type.
We’ll use the PerformanceTimeline to fetch ResourceTiming data (and UserTiming data).
Back to ResourceTiming
ResourceTiming takes its inspiration from the NavigationTiming timeline.
Here are the phases a single resource would go through during the fetch process:
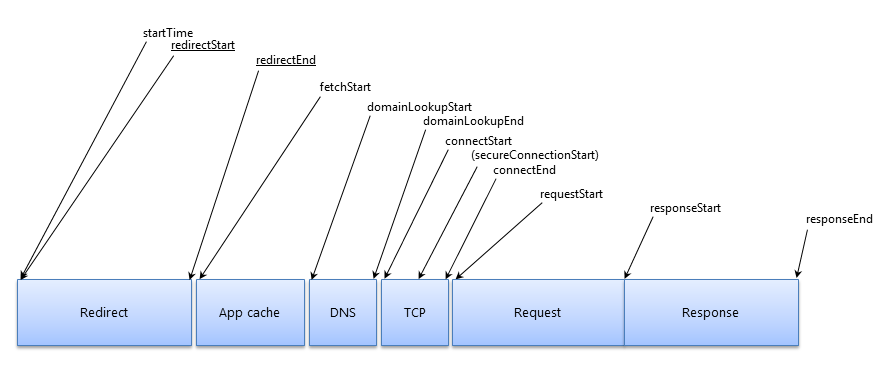

To fetch all of the resources on a page, you simply call one of the PerformanceTimeline methods:
var resources = window.performance.getEntriesByType("resource");
/* eg:
[
{
name: "https://www.foo.com/foo.png",
entryType: "resource",
startTime: 566.357000003336,
duration: 4.275999992387369,
initiatorType: "img",
nextHopProtocol: "h2",
workerStart: 300.0,
redirectEnd: 0,
redirectStart: 0,
fetchStart: 566.357000003336,
domainLookupStart: 566.357000003336,
domainLookupEnd: 566.357000003336,
connectStart: 566.357000003336,
secureConnectionStart: 0,
connectEnd: 566.357000003336,
requestStart: 568.4959999925923,
responseStart: 569.4220000004862,
responseEnd: 570.6329999957234,
transferSize: 1000,
encodedBodySize: 1000,
decodedBodySize: 1000,
}, ...
]
*/Please note that all of the timestamps are DOMHighResTimeStamps, so they are relative to window.performance.timing.navigationStart or window.performance.timeOrigin. Thus a value of 500 means 500 milliseconds after the page load started.
Here is a description of all of the ResourceTiming attributes:
nameis the fully-resolved URL of the attribute (relative URLs in your HTML will be expanded to include the full protocol, domain name and path)entryTypewill always be"resource"for ResourceTiming entriesstartTimeis the time the resource started being fetched (e.g. offset from theperformance.timeOrigin)durationis the overall time required to fetch the resourceinitiatorTypeis thelocalNameof the element that initiated the fetch of the resource (see details below)nextHopProtocol: ALPN Protocol ID such ashttp/0.9http/1.0http/1.1h2hqspdy/3(ResourceTiming Level 2)workerStartis the time immediately before the active Service Worker received thefetchevent, if a ServiceWorker is installedredirectStartandredirectEndencompass the time it took to fetch any previous resources that redirected to the final one listed. If either timestamp is0, there were no redirects, or one of the redirects wasn’t from the same origin as this resource.fetchStartis the time this specific resource started being fetched, not including redirectsdomainLookupStartanddomainLookupEndare the timestamps for DNS lookupsconnectStartandconnectEndare timestamps for the TCP connectionsecureConnectionStartis the start timestamp of the SSL handshake, if any. If the connection was over HTTP, or if the browser doesn’t support this timestamp (eg. Internet Explorer), it will be0.requestStartis the timestamp that the browser started to request the resource from the remote serverresponseStartandresponseEndare the timestamps for the start of the response and when it finished downloadingtransferSize: Bytes transferred for the HTTP response header and content body (ResourceTiming Level 2)decodedBodySize: Size of the body after removing any applied content-codings (ResourceTiming Level 2)encodedBodySize: Size of the body after prior to removing any applied content-codings (ResourceTiming Level 2)
duration includes the time it took to fetch all redirected resources (if any) as well as the final resource. To track the overall time it took to fetch just the final resource, you may want to use (responseEnd – fetchStart).
ResourceTiming does not (yet) include attributes that expose the HTTP status code of the resource (for privacy concerns).
Initiator Types
initiatorType is the localName of the element that fetched the resource — in other words, the name of the associated HTML element.
The most common values seen for this attribute are:
imglinkscriptcss:url(),@importxmlhttprequestiframe(known assubdocumentin some versions of IE)bodyinputframeobjectimagebeaconfetchvideoaudiosourcetrackembedeventsourcenavigationotheruse
It’s important to note the initiatorType is not a "Content Type". It is the element that triggered the fetch, not the type of content fetched.
As an example, some of the above values can be confusing at first glance. For example, A .css file may have an initiatorType of "link" or "css" because it can either be fetched via a <link> tag or via an @import in a CSS file. While an initiatorType of "css" might actually be a foo.jpg image, because CSS fetched an image.
The iframe initiator type is for <IFRAME>s on the page, and the duration will be how long it took to load that frame’s HTML (e.g. how long it took for responseEnd of the HTML). It will not include the time it took for the <IFRAME> itself to fire its onload event, so resources fetched within the <IFRAME> will not be represented in an iframe‘s duration. (Example test case)
Here’s a list of common HTML elements and JavaScript APIs and what initiatorType they should map to:
<img src="...">:img<img srcset="...">:img<link rel="stylesheet" href="...">:link<link rel="prefetch" href="...">:link<link rel="preload" href="...">:link<link rel="prerender" href="...">:link<link rel="manfiest" href="...">:link<script src="...">:script- CSS
@font-face { src: url(...) }:css - CSS
background: url(...):css - CSS
@import url(...):css - CSS
cursor: url(...):css - CSS
list-style-image: url(...):css <body background=''>:body<input src=''>:inputXMLHttpRequest.open(...):xmlhttprequest<iframe src="...">:iframe<frame src="...">:frame<object>:object<svg><image xlink:href="...">:image<svg><use>:usenavigator.sendBeacon(...):beaconfetch(...):fetch<video src="...">:video<video poster="...">:video<video><source src="..."></video>:source<audio src="...">:audio<audio><source src="..."></audio>:source<picture><source srcset="..."></picture>:source<picture><img src="..."></picture>:img<picture><img srcsec="..."></picture>:img<track src="...">:track<embed src="...">:embedfavicon.ico:link- EventSource:
eventsource
Not all browsers correctly report the initiatorType for the above resources. See this web-platform-tests test case for details.
What Resources are Included
All of the resources that your browser fetches to construct the page should be listed in the ResourceTiming data. This includes, but is not limited to images, scripts, css, fonts, videos, IFRAMEs and XHRs.
Some browsers (eg. Internet Explorer) may include other non-fetched resources, such as about:blank and javascript: URLs in the ResourceTiming data. This is likely a bug and may be fixed in upcoming versions, but you may want to filter out non-http: and https: protocols.
Additionally, some browser extensions may trigger downloads and thus you may see some of those downloads in your ResourceTiming data as well.
Not all resources will be fetched successfully. There might have been a networking error, due to a DNS, TCP or SSL/TLS negotiation failure. Or, the server might return a 4xx or 5xx response. How this information is surfaced in ResourceTiming depends on the browser:
- DNS failure (cross-origin)
- Chrome <= 78: No ResourceTiming entry
- Chrome >= 79:
domainLookupStartthroughresponseStartare0.responseEndanddurationare non-zero. - Internet Explorer:
domainLookupStartthroughresponseStartare0.responseEndanddurationare non-zero. - Edge:
domainLookupStartthroughresponseStartare0.responseEndanddurationare non-zero. - Firefox:
domainLookupStartthroughresponseStartare0.durationis0in some cases.responseEndis non-zero. - Safari: No ResourceTiming entry
- TCP failure (cross-origin)
- Chrome <= 78: No ResourceTiming entry
- Chrome >= 79:
domainLookupStartthroughresponseStartare0.responseEndanddurationare non-zero. - Internet Explorer:
domainLookupStartthroughresponseStartare0.responseEndanddurationare non-zero. - Edge:
domainLookupStartthroughresponseStartare0.responseEndanddurationare non-zero. - Firefox:
domainLookupStartthroughresponseStartanddurationare0.responseEndis non-zero. - Safari: No ResourceTiming entry
- SSL failure (cross-origin)
- Chrome <= 78: No ResourceTiming entry
- Chrome >= 79:
domainLookupStartthroughresponseStartare0.responseEndanddurationare non-zero. - Internet Explorer:
domainLookupStartthroughresponseStartare0.responseEndanddurationare non-zero. - Edge:
domainLookupStartthroughresponseStartare0.responseEndanddurationare non-zero. - Firefox:
domainLookupStartthroughresponseStartanddurationare0.responseEndis non-zero. - Safari: No ResourceTiming entry
- 4xx/5xx response (same-origin)
- Chrome <= 78: No ResourceTiming entry
- Chrome >= 79: All timestamps are non-zero.
- Internet Explorer: All timestamps are non-zero.
- Edge: All timestamps are non-zero.
- Firefox: All timestamps are non-zero.
- Safari <= 12: No ResourceTiming entry.
- Safari >= 13: All timestamps are non-zero.
- 4xx/5xx response (cross-origin)
- Chrome <= 78: No ResourceTiming entry
- Chrome >= 79: All timestamps are non-zero.
- Internet Explorer:
startTime,fetchStart,responseEndanddurationare non-zero. - Edge:
startTime,fetchStart,responseEndanddurationare non-zero. - Firefox:
startTime,fetchStart,responseEndanddurationare non-zero. - Safari <= 12: No ResourceTiming entry.
- Safari >= 13: All timestamps are non-zero.
The working group is attempting to get these behaviors more consistent across browsers. You can read this post for further details as well as inconsistencies found. See the browser bugs section for relevant bugs.
Note that the root page (your HTML) is not included in ResourceTiming. You can get all of that data from NavigationTiming.
An additional set of resources that may also be missing from ResourceTiming are resources fetched by cross-origin stylesheets fetched with no-cors policy.
There are a few additional reasons why a resource might not be in the ResourceTiming data. See the Crawling IFRAMEs and Timing-Allow-Origin sections for more details, or read the ResourceTiming Visibility post for an in-depth look.
Crawling IFRAMEs
There are two important caveats when working with ResourceTiming data:
- Each
<IFRAME>on the page will only report on its own resources, so you must look at every frame’sperformance.getEntriesByType("resource") - You cannot access
frame.performance.getEntriesByType()in a cross-origin frame
If you want to capture all of the resources that were fetched for a page load, you need to crawl all of the frames on the page (and sub-frames, etc), and join their entries to the main window’s.
This gist shows a naive way of crawling all frames. For a version that deals with all of the complexities of the crawl, such as adjusting resources in each frame to the correct startTime, you should check out Boomerang’s restiming.js plugin.
However, even if you attempt to crawl all frames on the page, many pages include third-party scripts, libraries, ads, and other content that loads within cross-origin frames. We have no way of accessing the ResourceTiming data from these frames. Over 30% of resources in the Alexa Top 1000 are completely invisible to ResourceTiming because they’re loaded in a cross-origin frame.
Please see my in-depth post on ResourceTiming Visibility for details on how this might affect you, and suggested workarounds.
Cached Resources
Cached resources will show up in ResourceTiming right along side resources that were fetched from the network.
For browsers that do not support ResourceTiming Level 2 with the content size attributes, there’s no direct indicator for the resource that it was served from the cache. In practice, resources with a very short duration (say under 30 milliseconds) are likely to have been served from the browser’s cache. They might take a few milliseconds due to disk latencies.
Browsers that support ResourceTiming Level 2 expose the content size attributes, which gives us a lot more information about the cache state of each resource. We can look at transferSize to determine cache hits.
Here is example code to determine cache hit status:
function isCacheHit() {
// if we transferred bytes, it must not be a cache hit
// (will return false for 304 Not Modified)
if (transferSize > 0) return false;
// if the body size is non-zero, it must mean this is a
// ResourceTiming2 browser, this was same-origin or TAO,
// and transferSize was 0, so it was in the cache
if (decodedBodySize > 0) return true;
// fall back to duration checking (non-RT2 or cross-origin)
return duration < 30;
}This algorithm isn’t perfect, but probably covers 99% of cases.
Note that conditional validations that return a 304 Not Modifed would be considered a cache miss with the above algorithm.
304 Not Modified
Conditionally fetched resources (with an If-Modified-Since or Etag header) might return a 304 Not Modified response.
In this case, the tranferSize might be small because it just reflects the 304 Not Modified response and no content body. transferSize might be less than the encodedBodySize in this case.
encodedBodySize and decodedBodySize should be the body size of the previously-cached resource.
(there is a Chrome 65 browser bug that might result in the encodedBodySize and decodedBodySize being 0)
Here is example code to detect 304s:
function is304() {
if (encodedBodySize > 0 &&
tranferSize > 0 &&
tranferSize < encodedBodySize) {
return true;
}
// unknown
return null;
}The ResourceTiming Buffer
There is a ResourceTiming buffer (per document / IFRAME) that stops filling after its limit is reached. By default, all modern browsers (except Internet Explorer / Edge) currently set this limit to 150 entries (per frame). Internet Explorer 10+ and Edge default to 500 entries (per frame). Some browsers may have also updated their default to 250 entries per frame.
The reasoning behind limiting the number of entries is to ensure that, for the vast majority of websites that are not consuming ResourceTiming entries, the browser’s memory isn’t consumed indefinitely holding on to a lot of this information. In addition, for sites that periodically fetch new resources (such as XHR polling), we would’t want the ResourceTiming buffer to grow unbound.
Thus, if you will be consuming ResourceTiming data, you need to have awareness of the buffer. If your site only downloads a handful of resources for each page load (< 100), and does nothing afterwards, you probably won’t hit the limit.
However, if your site downloads over a hundred resources, or you want to be able to monitor for resources fetched on an ongoing basis, you can do one of three things.
First, you can listen for the onresourcetimingbufferfull event which gets fired on the document when the buffer is full. You can then use setResourceTimingBufferSize(n) or clearResourceTimings() to resize or clear the buffer.
As an example, to keep the buffer size at 150 yet continue tracking resources after the first 150 resources were added, you could do something like this;
if ("performance" in window) {
function onBufferFull() {
var latestEntries = performance.getEntriesByType("resource");
performance.clearResourceTimings();
// analyze or beacon latestEntries, etc
}
performance.onresourcetimingbufferfull = performance.onwebkitresourcetimingbufferfull = onBufferFull;
}Note onresourcetimingbufferfull is not currently supported in Internet Explorer (10, 11 or Edge).
If your site is on the verge of 150 resources, and you don’t want to manage the buffer, you could also just safely increase the buffer size to something reasonable in your HTML header:
<html><head>
<script>
if ("performance" in window
&& window.performance
&& window.performance.setResourceTimingBufferSize) {
performance.setResourceTimingBufferSize(300);
}
</script>
...
</head>...(you should do this for any <iframe> that might load more than 150 resources too)
Don’t just setResourceTimingBufferSize(99999999) as this could grow your visitors’s browser’s memory unnecessarily.
Finally, you can also use a PerformanceObserver to manage your own "buffer" of ResourceTiming data.
Note: Some browsers are starting up update the default limit of 150 resources to 250 resources instead.
Timing-Allow-Origin
A cross-origin resource is any resource that doesn’t originate from the same domain as the page. For example, if your visitor is on http://foo.com/ and you’ve fetched resources from http://cdn.foo.com or http://mycdn.com, those resources will both be considered cross-origin.
By default, cross-origin resources only expose timestamps for the following attributes:
startTime(will equalfetchStart)fetchStartresponseEndduration
This is to protect your privacy (so an attacker can’t load random URLs to see where you’ve been).
This means that all of the following attributes will be 0 for cross-origin resources:
redirectStartredirectEnddomainLookupStartdomainLookupEndconnectStartconnectEndsecureConnectionStartrequestStartresponseStart
In addition, all size information will be 0 for cross-origin resources:
transferSizeencodedBodySizedecodedBodySize
In addition, cross-origin resources that redirected will have a startTime that only reflects the final resource — startTime will equal fetchStart instead of redirectStart. This means the time of any redirect(s) will be hidden from ResourceTiming.
Luckily, if you control the domains you’re fetching other resources from, you can overwrite this default precaution by sending a Timing-Allow-Origin HTTP response header:
Timing-Allow-Origin = "Timing-Allow-Origin" ":" origin-list-or-null | "*"In practice, most people that send the Timing-Allow-Origin HTTP header just send a wildcard origin:
Timing-Allow-Origin: *So if you’re serving any of your content from another domain name, i.e. from a CDN, it is strongly recommended that you set the Timing-Allow-Origin header for those responses.
Thankfully, third-party libraries for widgets, ads, analytics, etc are starting to set the header on their content. Only about 13% currently do, but this is growing (according to the HTTP Archive). Notably, Google, Facebook, Disqus, and mPulse send this header for their scripts.
Blocking Time
Browsers will only open a limited number of connections to each unique origin (protocol/server name/port) when downloading resources.
If there are more resources than the # of connections, the later resources will be "blocking", waiting for their turn to download.
Blocking time is generally seen as "missing periods" (non-zero durations) that occur between connectEnd and requestStart (when waiting on a Keep-Alive TCP connection to reuse), or between fetchStart and domainLookupStart (when waiting on things like the browser’s cache).
The duration attribute includes Blocking time. So in general, you may not want to use duration if you’re only interested in actual network timings.
Unfortunately, duration, startTime and responseEnd are the only attributes you get with cross-origin resources, so you can’t easily subtract out Blocking time from cross-origin resources.
To calculate Blocking time, you would do something like this:
var blockingTime = 0;
if (res.connectEnd && res.connectEnd === res.fetchStart) {
blockingTime = res.requestStart - res.connectEnd;
} else if (res.domainLookupStart) {
blockingTime = res.domainLookupStart - res.fetchStart;
}Content Sizes
Beginning with ResourceTiming 2, content sizes are included for all same-origin or Timing-Allow-Origin resources:
transferSize: Bytes transferred for HTTP response header and content bodydecodedBodySize: Size of the body after removing any applied content-codingsencodedBodySize: Size of the body after prior to removing any applied content-codings
Some notes:
- If
transferSizeis0, and timestamps likeresponseStartare filled in, the resource was served from the cache - If
transferSizeis0, but timestamps likeresponseStartare also0, the resource was cross-origin, so you should look at the cached state algorithm to determine its cache state transferSizemight be less thanencodedBodySizein cases where a conditional validation occurred (e.g.304 Not Modified). In this case,transferSizewould be the size of the304headers, whileencodedBodySizewould be the size of the cached response body from the previous request.- If
encodedBodySizeanddecodedBodySizeare non-0and differ, the content was compressed (e.g. gzip or Brotli) encodedBodySizemight be0in some cases (e.g.HTTP 204 (No Content)or 3XX responses)- See the ServiceWorker section for details when a ServiceWorker is involved
ServiceWorkers
If you are using ServiceWorkers in your app, you can get information about the time the ServiceWorker activated (fetch was fired) for each resource via the workerStart attribute.
The difference between workerStart and fetchStart is the processing time of the ServiceWorker:
var workerProcessingTime = 0;
if (res.workerStart && res.fetchStart) {
workerProcessingTime = res.fetchStart - res.workerStart;
}When a ServiceWorker is active for a resource, the size attributes of transferSize, encodedBodySize and decodedBodySize are under-specified, inconsistent between browsers, and will often be exactly 0 even when bytes are transferred. There is an open NavigationTiming issue tracking this. In addition, the timing attributes may be under-specified in some cases, with a separate issue tracking that.
Compressing ResourceTiming Data
The HTTP Archive tells us there are about 100 HTTP resources on average, per page, with an average URL length of 85 bytes.
On average, each resource is ~ 500 bytes when JSON.stringify()‘d.
That means you could expect around 45 KB of ResourceTiming data per page load on the "average" site.
If you’re considering beaconing ResourceTiming data back to your own servers for analysis, you may want to consider compressing it first.
There’s a couple things you can do to compress the data, and I’ve written about these methods already. I’ve shared an open-source script that can compress ResourceTiming data that looks like this:
{
"responseEnd":323.1100000002698,
"responseStart":300.5000000000000,
"requestStart":252.68599999981234,
"secureConnectionStart":0,
"connectEnd":0,
"connectStart":0,
"domainLookupEnd":0,
"domainLookupStart":0,
"fetchStart":252.68599999981234,
"redirectEnd":0,
"redirectStart":0,
"duration":71.42400000045745,
"startTime":252.68599999981234,
"entryType":"resource",
"initiatorType":"script",
"name":"http://foo.com/js/foo.js"
}To something much smaller, like this (which contains 3 resources):
{
"http://": {
"foo.com/": {
"js/foo.js": "370,1z,1c",
"css/foo.css": "48c,5k,14"
},
"moo.com/moo.gif": "312,34,56"
}
}Overall, we can compresses ResourceTiming data down to about 15% of its original size.
Example code to do this compression is available on github.
See also the discussion on payload sizes in my Beaconing In Practice article.
PerformanceObserver
Instead of using performance.getEntriesByType("resource") to fetch all of the current resources from the ResourceTiming buffer, you could instead use a PerformanceObserver to get notified about all fetches.
Example usage:
if (typeof window.PerformanceObserver === "function") {
var resourceTimings = [];
var observer = new PerformanceObserver(function(entries) {
Array.prototype.push.apply(resourceTimings, entries.getEntries());
});
observer.observe({entryTypes: ['resource']});
}The benefits of using a PerformanceObserver are:
- You have stricter control over buffering old entries (if you want to buffer at all)
- If there are multiple scripts or libraries on the page trying to manage the ResourceTiming buffer (by setting its size or clearing it), the PerformanceObserver won’t be affected by it.
However, there are two major challenges with using a PerformanceObserver for ResourceTiming:
- You’ll need to register the PerformanceObserver before everything else on the page, ideally via an inline-
<script>tag in your page’s<head>. Otherwise, requests that fire before the PerformanceObserver initializes won’t be delivered to the callback. There is some work being done to add abuffered: trueoption, but it is not yet implemented in browsers. In the meantime, you could callobserver.observe()and then immediately callperformance.getEntriesByType("resource")to get the current buffer. - Since each frame on the page maintains its own buffer of ResoruceTiming entries, and its own PerformanceObserver list, you will need to register a PerformanceObserver in all frames on the page, including child frames, grandchild frames, etc. This results in a race condition, where you need to either monitor the page for all
<iframe>s being created an immediately hook a PerformanceObserver in their window, or, you’ll have to crawl all of the frames later and getperformance.getEntriesByType("resource")anyways. There are some thoughts about adding abubbles: trueflag to make this easier.
Use Cases
Now that ResourceTiming data is available in the browser in an accurate and reliable manner, there are a lot of things you can do with the information. Here are some ideas:
- Send all ResourceTimings to your backend analytics
- Raise an analytics event if any resource takes over X seconds to download (and trend this data)
- Watch specific resources (eg third-party ads or analytics) and complain if they are slow
- Monitor the overall health of your DNS infrastructure by beaconing DNS resolve time per-domain
- Look for production resource errors (eg 4xx/5xx) in browsers that add errors to the buffer it (IE/Firefox)
- Use ResourceTiming to determine your site’s "visual complete" metric by looking at timings of all above-the-fold images
The possibilities are nearly endless. Please leave a comment with how you’re using ResourceTiming data.
DIY and Open-Source
Here are several interesting DIY / open-source solutions that utilize ResourceTiming data:
Andy Davies’ Waterfall.js shows a waterfall of any page’s resources via a bookmarklet: github.com/andydavies/waterfall

Mark Zeman’s Heatmap bookmarklet / Chrome extension gives a heatmap of when images loaded on your page: github.com/zeman/perfmap

Nurun’s Performance Bookmarklet breaks down your resources and creates a waterfall and some interesting charts: github.com/nurun/performance-bookmarklet
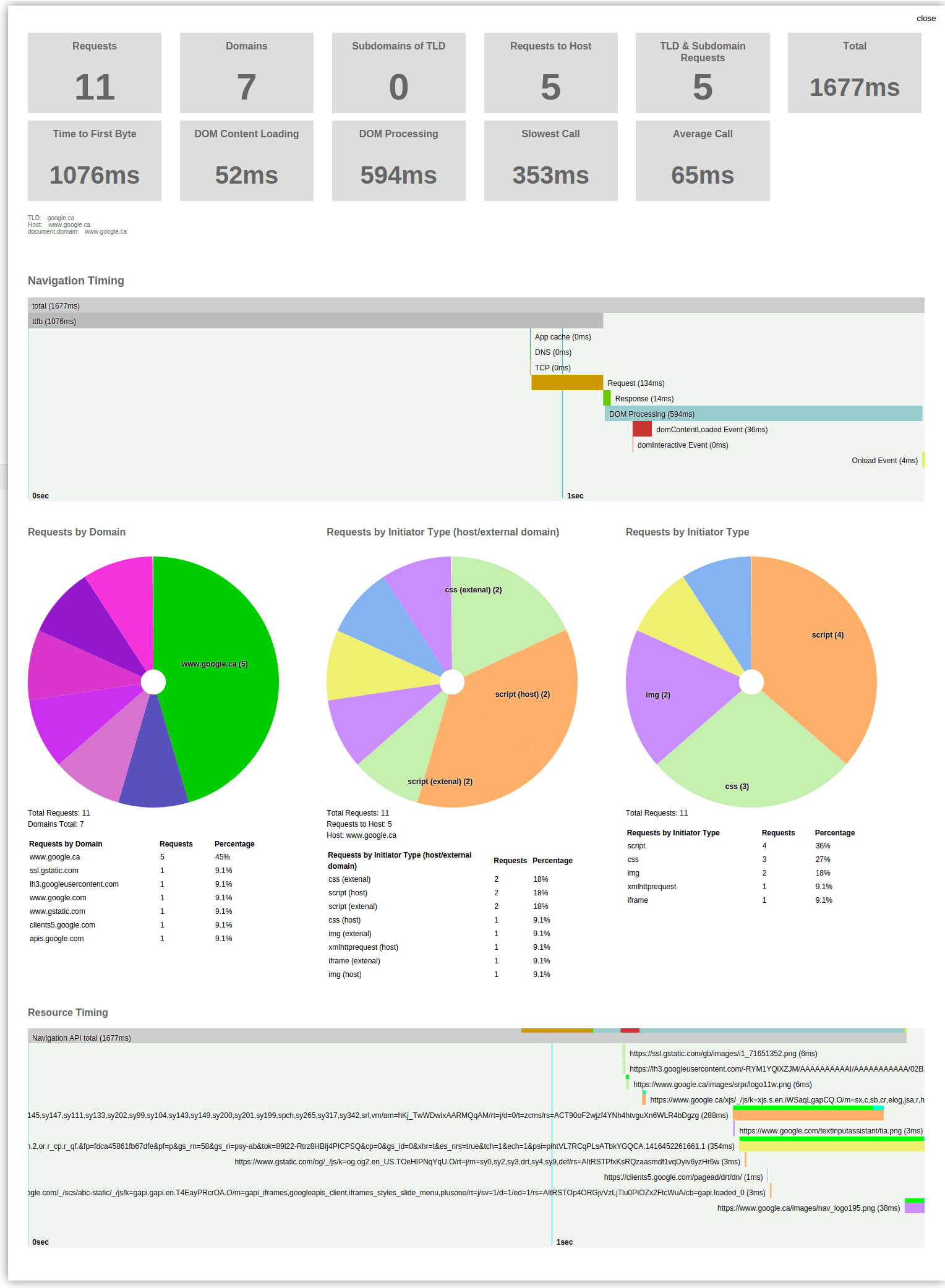

Boomerang (which I work on) also captures ResourceTiming data and beacons it back to your backend analytics server: github.com/lognormal/boomerang
Commercial Solutions
If you don’t want to build or manage a DIY / Open-Source solution to gather ResourceTiming data, there are many great commercial services available.
Disclaimer: I work at Akamai, on mPulse and Boomerang
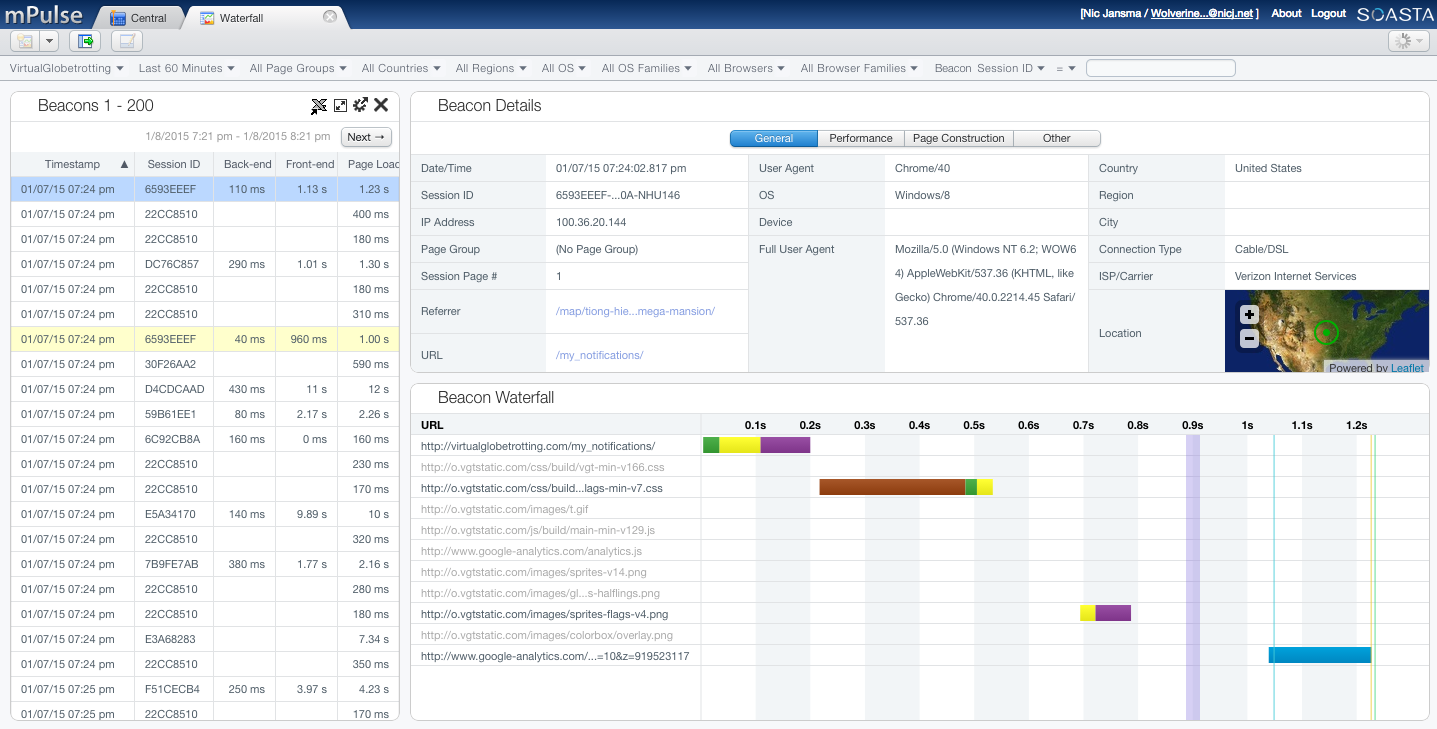
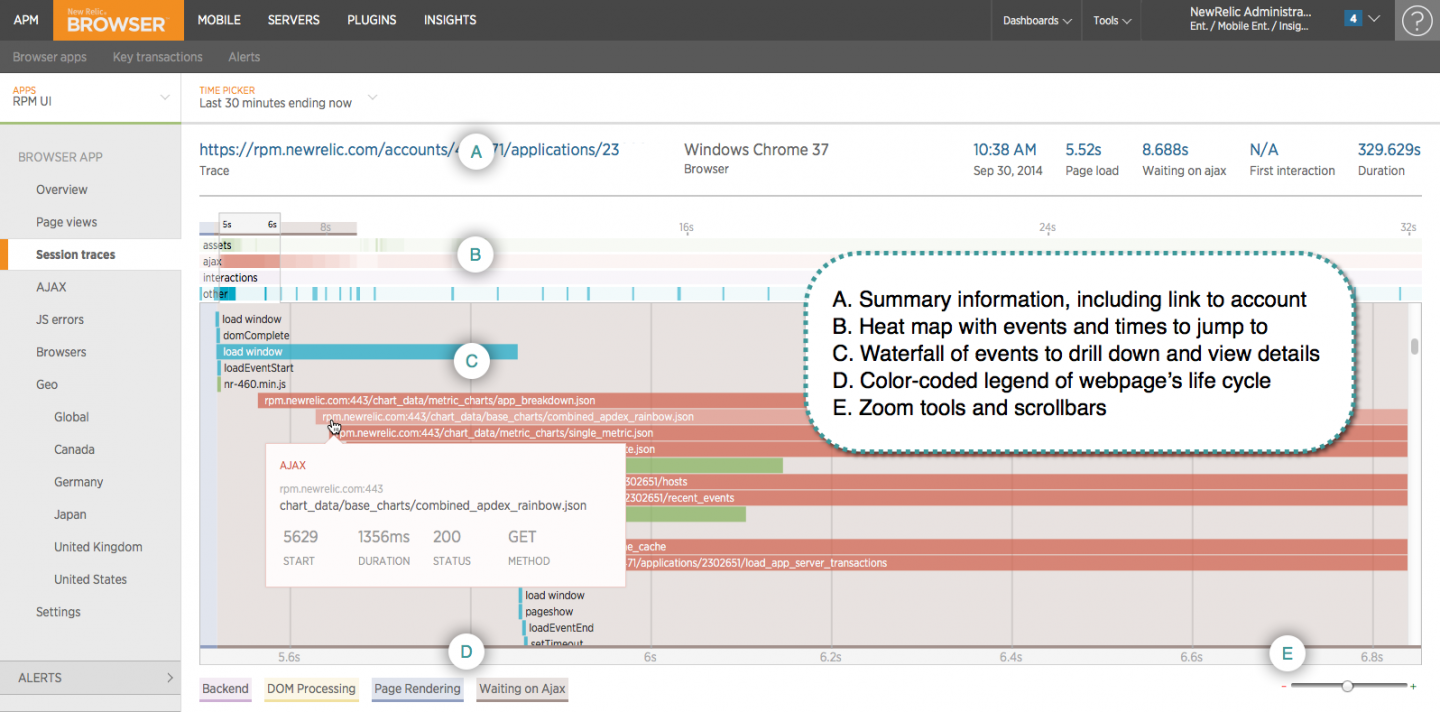
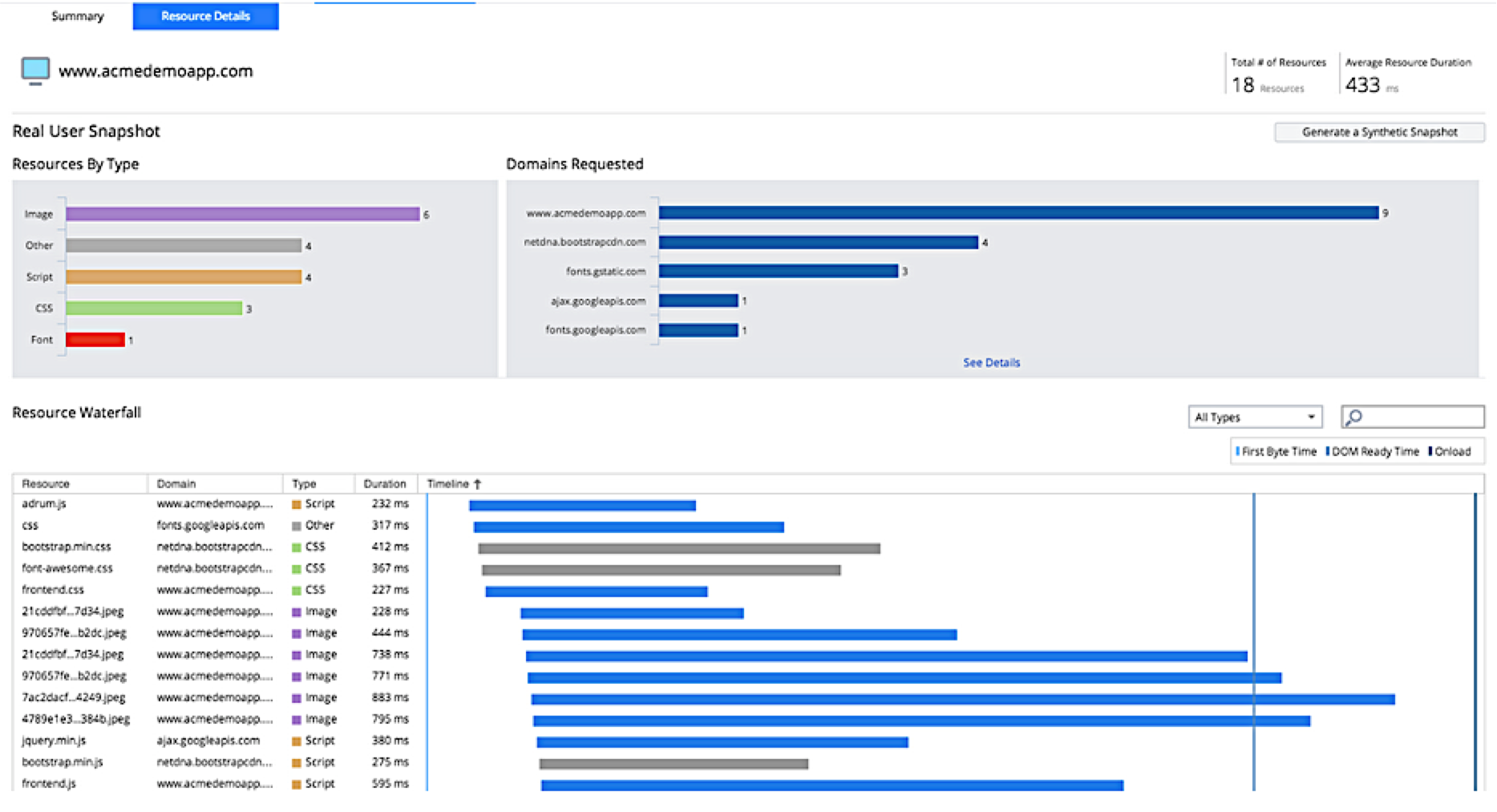
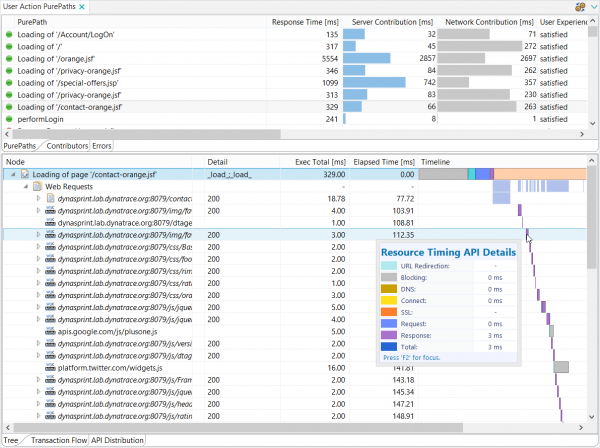
Akamai mPulse captures 100% of your site’s traffic and gives you Waterfalls for each visit:




Availability
ResourceTiming is available in most modern browsers. According to caniuse.com, 96.7% of world-wide browser market share supports ResourceTiming (as of May 2021). This includes Internet Explorer 10+, Edge, Firefox 36+, Chrome 25+, Opera 15+, Safari 11 and Android Browser 4.4+.


There are no polyfills available for ResourceTiming, as the data is just simply not available if the browser doesn’t expose it.
Tips
Here are some additional (and re-iterated) tips for using ResourceTiming data:
- For many sites, most of your content will not be same-origin, so ensure all of your CDNs and third-party libraries send the
Timing-Allow-OriginHTTP response header. - Each
IFRAMEwill have its own ResourceTiming data, and those resources won’t be included in the parent FRAME/document. You’ll need to traverse the document frames to get all resources. See github.com/nicjansma/resourcetiming-compression.js. - Resources loaded from cross-origin frames will not be visible
- ResourceTiming data does not ((yet)[https://github.com/w3c/resource-timing/issues/90]) include the HTTP response code for privacy concerns.
- If you’re going to be managing the ResourceTiming buffer, make sure no other scripts are managing it as well (eg third-party analytics scripts). Otherwise, you may have two listeners for
onresourcetimingbufferfullstomping on each other. - The
durationattribute includes Blocking time (when a resource is blocked behind other resources on the same socket). about:blankandjavascript:URLs may be in the ResourceTiming data for some browsers, and you may want to filter them out.- Browser extensions may show up in ResourceTiming data, if they initiate downloads. We’ve seen Skype and other extensions show up.
ResourceTiming Browser Bugs
Browsers aren’t perfect, and unfortunately there some outstanding browser bugs around ResourceTiming data. Here are some of the known ones (some of which may have been fixed the time you read this):
- All browsers have issues with the
initiatorTypeattribute - Chrome:
sendBeacon()does not add entries to ResourceTiming (fixed) - Chrome:
fetch()resources sometimes don’t get added to the ResourceTiming timeline - Chrome: ResourceTiming encodedBodySize and decodedBodySize are 0 for 304 Not Modified responses
- Chrome: ResourceTiming is affected by page activity
- Chrome: secureConnectionStart is 0 but it should be a timestamp
- Chrome: secureConnectionStart does not report start of HTTPS handshake
- Chrome: ResourceTiming does not work wih Preconnect
- Chrome: PerformanceResourceTiming.initiatorType === "" when used with the fetch API
- Chrome: ResourceTiming (DNS) inaccurate when using HTTP/2
- Chrome: Missing PerformanceResourceTiming entries for Requests that don’t receive a Response
- Chrome: Zero-byte IFRAMEs do not create PerformanceResourceTiming entries
- Edge: Incorrect behavior populating ResourceTimings performance buffer
- Edge: pageshow is firing before image is visible on the page and its ResourceTiming data is ready
- Edge: Edge exposing TAO-restricted timings when port differs
- Safari: Should surface entries for failed requests (DNS, TCP, SSL, 4xx, 5xx)
- Safari: Zero-byte IFRAMEs do not create PerformanceResourceTiming entries
- Safari: Resource Timing: secureConnectionStart == 0 when a connection is re-used
- Safari: Resource Timing: Duration is 0 in many cases
- Firefox: ResourceTiming duration should be non-0 for failed DNS, TCP, SSL
- Firefox: ResourceTiming secureConnectionStart is 0 for some HTTPS connections
Sidebar – it’s great that browser vendors are tracking these issues publicly.
Conclusion
ResourceTiming exposes accurate performance metrics for all of the resources fetched on your page. You can use this data for a variety of scenarios, from investigating the performance of your third-party libraries to taking specific actions when resources aren’t performing according to your performance goals.
Next up: Using UserTiming data to expose custom metrics for your JavaScript apps in a standardized way.
Other articles in this series:
More resources:
DOMHighResTimeStampW3C specification- ResourceTiming W3C specification
- PerformanceTimeline W3C specification
- Compressing ResourceTiming
- Compressing UserTiming
Updates
- 2016-01-03: Updated Firefox’s 404 and DNS behavior via Aaron Peters
- 2018-04:
- Updated the
PerformanceResourceTiminginterface for ResourceTiming (Level 2) and descriptions of ResourceTiming 2 attributes - Updated an incorrect statement about
initiatorType='iframe'. Previously this document stated that thedurationwould include the time it took for the<IFRAME>to download static embedded resources. This is not correct.durationonly includes the time it takes to download the<IFRAME>HTML bytes (throughresponseEndof the HTML, so it does not include theonloadduration of the<IFRAME>). - Updated list of attributes that are
0for cross-origin resources (to include size attributes) - Added a note with examples on how to crawl frames
- Added a note on ResourceTiming Visibility and how cross-origin frames affect ResourceTiming
- Removed some notes about older versions of Chrome
- Added section on Content Sizes
- Updated the Cached Resources section to add an algorithm for ResourceTiming2 data
- Updated
initiatorTypelist as well as added a map of common elements to whatinitiatorTypethey would be - Added a note about ResourceTiming missing resources fetched by cross-origin stylesheets fetched with no-cors policy
- Added note about
startTimemissing when there are redirects with no Timing-Allow-Origin - Added a section for
304 Not Modifiedresponses - Added a section on
PerformanceObserver - Updated the ServiceWorker section
- Added a section on Browser Bugs
- Updated caniuse.com market share
- Updated the
- 2018-06:
- Updated note that IE/Edge have a default buffer size of 500 entries
- Added note about change to increase recommended buffer size of 150 to 250
- 2019-01
- Added a Table of Contents
- Updated What Resources are Included based on recent research and inclusion of Safari.
- 2021-05
- Updated Content Sizes and ServiceWorker sections for how the former is affected by the later
- Updated caniuse.com market share
- Added some additional known browser bugs