Boomerang Performance Update
Table Of Contents
- Introduction
- Boomerang Loader Snippet Improvements
- ResourceTiming Compression Optimization
- Debug Messages
- Minification
- Cookie Size
- Cookie Access
- MD5 plugin
- SPA plugin
- Brotli
- Performance Test Suite
- Next
Boomerang is an open-source JavaScript library that measures the page load experience of real users, commonly called RUM (Real User Measurement).
Boomerang is used by thousands of websites large and small, either via the open-source library or as part of Akamai’s mPulse RUM service. With Boomerang running on billions of page loads a day, the developers behind Boomerang take pride in building a reliable and performant third-party library that everyone can use without being concerned about its measurements affecting their site.
Two years ago, we performed an audit of Boomerang’s performance, to help communicate the “cost” of including Boomerang on a page as a third-party script. In doing the audit, we found several areas of code that we wanted to improve, and have been working steadily to make it better for our customers.
This article highlights some of the improvements we’ve made in the last two years, and what we still want to work on next!
Boomerang Loader Snippet Improvements
We recommended loading Boomerang via our custom loader snippet. The snippet ensures Boomerang loads asynchronously and non-blocking, so it won’t affect the Page Load time. Version 10 (v10) of this snippet utilizes an IFRAME to host Boomerang, which gets it out of the critical path.
When we reviewed the performance impact of the snippet we found that on modern devices and browsers the snippet itself should take less than 10ms of CPU, but on older or slower devices it could take 20-40ms.
A significant portion of this CPU cost was creating a dynamic IFRAME and document.write()‘ing into it.
Last year, our team developed an updated version of the loader snippet we call Version 12 (v12), which utilizes Preload on modern browsers (instead of an IFRAME) to load Boomerang asynchronously. This avoids the majority of the CPU cost we saw when profiling the snippet.
As long as your browser supports Preload, the new loader snippet should have negligible CPU cost:
| Device | OS | Browser | Snippet v10 (ms) | Snippet v12 (ms) | Method |
|---|---|---|---|---|---|
| PC Desktop | Win 10 | Chrome 73 | 7 | 1 | Preload |
| PC Desktop | Win 10 | Firefox 66 | 3 | 3 | IFRAME |
| PC Desktop | Win 10 | IE 10 | 12 | 12 | IFRAME |
| PC Desktop | Win 10 | IE 11 | 14 | 14 | IFRAME |
| PC Desktop | Win 10 | Edge 44 | 8 | 1 | Preload |
| MacBook Pro (2017) | macOS High Sierra | Safari 12 | 3 | 1 | Preload |
| Galaxy S4 | Android 4 | Chrome 56 | 37 | 1 | Preload |
| Galaxy S8 | Android 8 | Chrome 73 | 9 | 1 | Preload |
| Galaxy S10 | Android 9 | Chrome 73 | 7 | 1 | Preload |
| iPhone 4 | iOS 7 | Safari 7 | 19 | 19 | IFRAME |
| iPhone 5s | iOS 11 | Safari 11 | 9 | 9 | IFRAME |
| iPhone 5s | iOS 12 | Safari 12 | 9 | 1 | Preload |
Browsers which don’t support Preload (such as IE and Firefox) will still use the IFRAME fallback, but it should still take minimal time to execute.
In addition, the new loader snippet is CSP-compliant, and brings some SEO improvements (i.e. creating an IFRAME in the <head> can confuse some web crawlers).
You can review the difference between the two versions here.
ResourceTiming Compression Optimization
Boomerang can collect ResourceTiming data for all of the resources on the page. We compress the data to reduce its size, but we found this was one of the most expensive things we did.
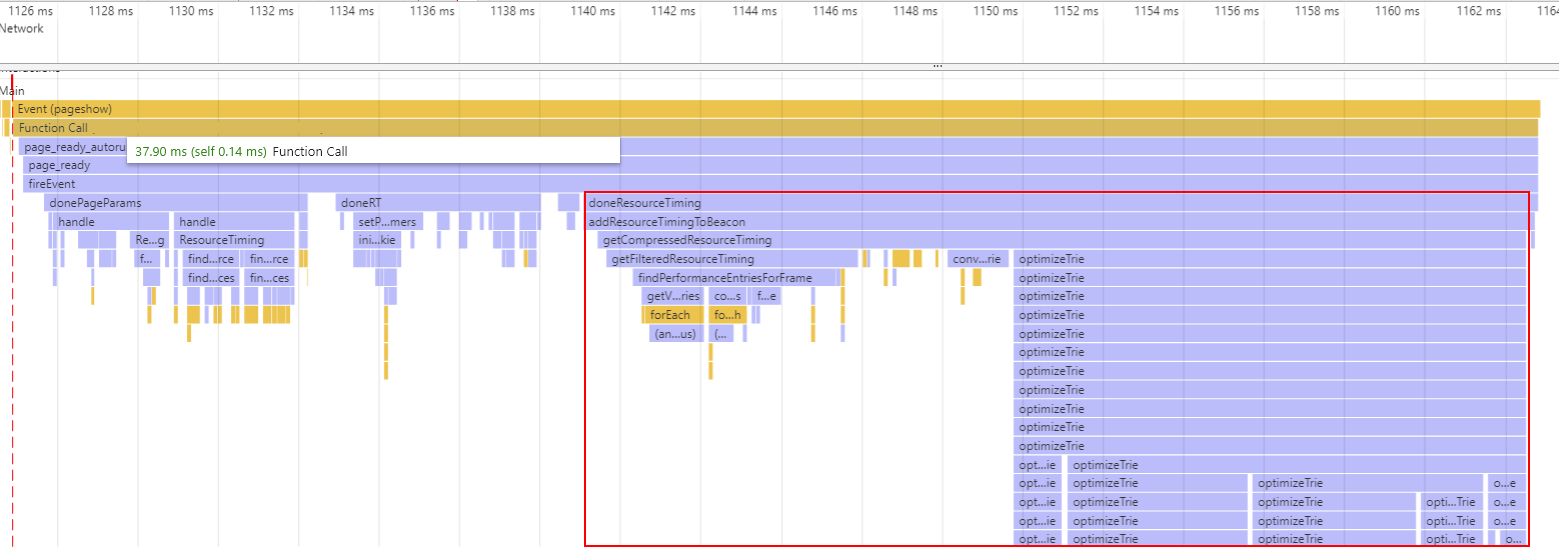
On some sites — especially those with hundreds of resources — our ResourceTiming compression could take 20-100ms or more. Most of the cost is in our optimizeTrie() function. Let’s take a look at what it does.
Say you have a list of ResourceTiming entries, i.e. resources fetched from a website:
http://site.com/
http://site.com/assets/js/main.js
http://site.com/assets/js/lib.js
http://site.com/assets/css/screen.css
We convert this list of URLs into an optimized Trie, a data structure that compresses common prefixes (i.e. http://site.com/ for all URLs above):
{"http://site.com/": {
"|": "[data]",
"assets/": {
"js/": {
"main.js": "[data]",
"lib.js": "[data]"
},
"css/screen.css": "[data]"
}
}
Originally, we were compressing a perfectly-optimized Trie — we would evaluate every character of every URL to find if there are other URLs that share the same prefix. This character iteration would create call stacks N deep, where N is the longest URL on the page. This is pretty costly to execute as you can imagine!
We switched this Trie optimization to instead split each URL at every "/" instead of every character. This leads to a slightly less optimized Trie (meaning, a few bytes larger), but it’s significantly faster. Call stacks are now only as deep as the number of slashes in the URL.
These optimizations are most significant on large sites (i.e. 100+ URLs): on sites where the ResourceTiming optimization was taking > 100ms (on desktop CPUs), changing to splitting at "/" reduced CPU time to ~25ms at only a 4% growth in data.
On less complex sites that used to take 25-35ms to compress this data, changing our algorithm reduced CPU time to just ~10ms at only 2-3% data growth.
Collecting ResourceTiming is still one of the more expensive operations that Boomerang does, but its costs are much less noticeable!
You can review our change here.
Debug Messages
Our community noticed that even in the production builds of Boomerang, the BOOMR.debug() debug messages were included in the minified JavaScript, even though they would never be echo’d to the console.
Stripping these messages from the build saw immediate size improvements:
- Original size (minified): 205,769 bytes
BOOMR.debug()and related messages removed: 196,125 bytes (-5%)
Gzipped:
- Original size (minified, gzipped): 60,133 bytes
BOOMR.debug()and related messages removed (minified, gzipped): 57,123 bytes (-6%)
Removing dead code is always a win!
You can review our change here.
Minification
For production builds, we used UglifyJS-2 to minify Boomerang.
Minification is incredibly powerful — in our case, our “debug” builds are over 800 KB, and are reduced to 191 KB on minification:
- Boomerang with all comments and debug code: 820,130 bytes
- Boomerang minified: 196,125 bytes (76% savings)
When Boomerang was first created, it used the YUI Compressor for minification. We switched to UglifyJS-2 in 2015 as it offered the best minification rate at the time.
UgifyJS-3 is now out, so we wanted to investigate if it (or any other tool) offered better minification in 2019.
After some experimentation, we changed from UglifyJS-2 to UglifyJS-3, while also enabling the ie8:true option for compatibility and compress.keep_fnames option to improve Boomerang Error reporting.
After all of these changes, Boomerang is 2,074 bytes larger uncompressed (because of ie8 and keep_fnames), though 723 bytes smaller once gzipped. Had we not enabled those compatibility options, Uglify-3 would’ve been 2,596 bytes smaller than Uglify-2. We decided the compatibility changes were worth it.
You can review this change here.
Our team also looked at the Closure compiler, and we estimate it would give us additional savings:
- UglifyJS-3: 47 KB brotli, 55 KB gzip
- Closure: 42 KB brotli, 47 KB gzip
Unfortunately, there are some optimizations in the Closure compiler that complain about parts of the Boomerang source code. Boomerang today can collect performance metrics on IE6+, and switching to Closure might reduce our support for older browsers.
Cookie Size
mPulse uses a first-party cookie RT to track mPulse sessions between pages, and for tracking Page Load time on browsers that don’t support NavigationTiming.
Here’s an example of what the cookie might look like in a modern browser. Our cookie consists of name-value pairs (~322 bytes):
dm=virtualglobetrotting.com
si=9563ee29-e809-4844-88df-d4e84697f475
ss=1537818004420
sl=1
tt=7556
obo=0
sh=1537818012102%3D1%3A0%3A7556
bcn=%2F%2F17d98a5a.akstat.io%2F
ld=1537818012103
nu=https%3A%2F%2Fvirtualglobetrotting.com%maps%2F
cl=1537818015199
r=https%3A%2F%2Fvirtualglobetrotting.com%2F
ul=1537818015211
We reviewed everything that we were storing in the cookie, and found a few areas for improvement.
The two biggest contributors to its size are the "nu" and "r" values, which are the URL of the next page the user is navigating to, and the referring page, respectively. This means the cookie will be at least as long as those two URLs.
We decided that we didn’t need to store the full URL in the cookie: we could use a hash instead, and compare the hashes on the next page. This can save a lot of bytes on longer-URL sites.
We were also able to reduce the size of all of the timestamps in the cookie by switching to Base36 encoding, and offsetting each timestamp by the start time ("ss"). We also removed some unused debugging data ("sh").
Example cookie after all of the above changes (~189 bytes, 41% smaller):
dm=virtualglobetrotting.com
si=9563ee29-e809-4844-88df-d4e84697f475
ss=jmgp4udg
sl=1
tt=5tw
obo=0
bcn=%2F%2F17d98a5a.akstat.io%2F
ld=5xf
nu=13f91b339af573feb2ad5f66c9d65fc7
cl=8bf
ul=8br
z=1
You can review our change here.
Cookie Access
As part of the 2017 Boomerang Performance Audit we found that Boomerang was reading/writing the Cookie multiple times during the page load, and the relevant functions were showing up frequently in CPU profiles:
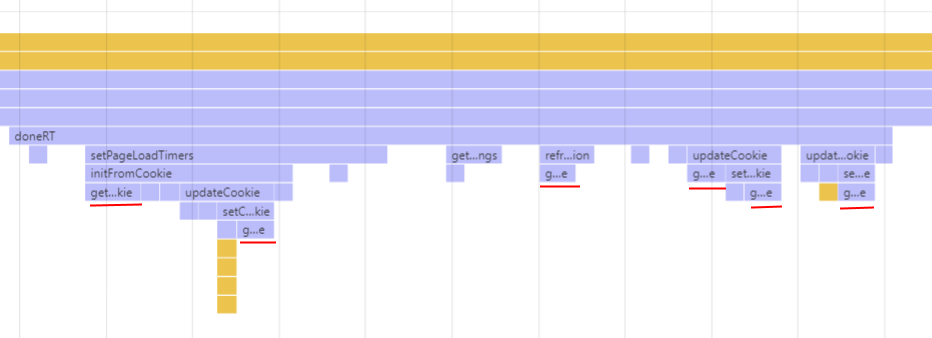
Upon review, we found that Boomerang was reading the RT cookie up to 21 times during a page load and setting it a further 8 times. This seemed… excessive. Cookie accesses may show up on CPU profiles because it can be accessing the disk to persist the data.
Through an audit of these reads/writes and some optimizations, we’ve been able to reduce this down to 2 reads and 4 writes, which is the minimal number we think are required to be reliable.
You can review our change here.
MD5 plugin
This improvement comes from our new Boomerang developer Tsvetan Stoychev. In his words:
“About 2 months ago we received a ticket in our GitHub repository about an issue developers experienced when they tried to build a Boomerang bundle that does not contain the Boomerang MD5 plugin. It was nothing critical but I started working on a small fix to make sure the issue doesn’t happen again in newer versions of Boomerang.
While working on the fix, I managed to understand the bigger picture and the use cases where we used the MD5 plugin. I saw an opportunity to replace MD5 implementation with an algorithm that doesn’t generate hashes as strong as MD5 but would still work in our use case.
The goal was to reduce the Boomerang bundle size and to keep things backward-compatible. I asked around in a group of professionals who do programming for IoT devices and received some good ideas about lightweight algorithms that could save a lot of bytes.
I looked at 2 candidates: CRC32 and FNV-1. The winner was a slightly modified version of FNV-1 and in terms of bytes it was 0.33 KB (uncompressed) compared to MD5, which was 8.17 KB (uncompressed). I also experimented with CRC32 but the JavaScript implementation was 2.55 KB (uncompressed) because the CRC32 source code contains a string of a CRC table that adds quite a few bytes. As a matter of fact, there is a way to use a smaller version that is 0.56 KB (uncompressed) where the CRC table is generated on the fly, but I found this version was adding more complexity and had a performance penalty when the CRC table was generated.
Let’s look at the data I gathered during my research where I compare performance, bytes and chances for collisions:
| # | Collisions | Size (uncompressed) | Hash Length | Hashes / Sec |
|---|---|---|---|---|
| MD5 | 0 | 8.17 KB | 32 | 35,397 |
| CRC32 | 8 | 2.55 KB | 9-10 | 253,680 |
| FNV-1 (original) | 3 | 0.33 KB | 9-10 | 180,056 |
| FNV-1 (modified) | 0 | 0.34 KB | 6-8 | 113,532 |
- Collision testing was performed on 500,000 unique URLs.
- Performance benchmark was performed with the help of jsPerf
FNV-1 modifications:
- In order to achieve better entropy for the FNV-1 algorithm, we concatenate the length of our input string with the end of the original FNV-1 generated hash.
- The FNV-1 output is actually a number that we convert to base 36 in the modified version in order to make the number’s string representation shorter.
Below is the final result in case you would like to test the modified version of FNV-1:
var fnv = function(string) {
string = encodeURIComponent(string);
var hval = 0x811c9dc5;
for (var i = 0; i < string.length; i++) {
hval = hval ^ string.charCodeAt(i);
hval += (hval << 1) + (hval << 4) + (hval << 7) + (hval << 8) + (hval << 24);
}
var hash = (hval >>> 0).toString() + string.length;
return parseInt(hash).toString(36);
}
You can review our change here.
SPA Plugin
This improvement comes from our Boomerang developer Nigel Heron, who’s been working on a large refactor (and simplification) of our Single Page App monitoring code. In his words:
“Boomerang had 4 SPA plugins: Angular, Ember, Backbone and History. The first 3 are SPA framework specific and hook into special functions in their respective frameworks to detect route changes (eg. Angular’s $routeChangeStart).
The History plugin could be used in 2 ways, either by hooking into the React Router framework’s history object or by hooking into the browser’s window.history object for use by any other framework that calls the window History API before issuing route changes.
As SPA frameworks have evolved over the years, calling into the History API before route changes has become standard. We determined that the timings observed by hooking History API calls vs hooking into framework specific events was negligible.
We modified the History plugin to remove React specific code and removed the 3 framework specific plugins from Boomerang.
This has simplified Boomerang’s SPA logic, simplified the configuration of Boomerang on SPA sites and as a bonus, has dropped the size of Boomerang!
| unminified | minified | gzip | |
|---|---|---|---|
| before | 796 KB | 202 KB | 57.27 KB |
| after | 779 KB | 200 KB | 57.07 KB |
You can review our change here.
Brotli
This is a fix that could be applied to any third-party library, but when we ran our audit two years ago, we had not yet enabled Brotli compression for boomerang.js delivery when using mPulse.
mPulse’s boomerang.js is delivered via the Akamai CDN, and we were able to utilize Akamai’s Resource Optimizer to automatically enable Brotli compression for our origin-gzip-compressed JavaScript URLs, with minimal effort. We should have done this sooner!
The over-the-wire byte savings of Brotli vs gzip are pretty significant. Taking the most recent build of Boomerang with all plugins enabled:
- gzip: 54,803 bytes
- brotli: 48,663 bytes (11.2% savings)
Brotli is now enabled for all boomerang.js downloads for mPulse customers.
(Over-the-wire byte size does not reduce the parse/compile/initialization time of Boomerang, and we’re still looking for additional ways of making Boomerang and its plugins smaller and more efficient)
Performance Test Suite
After spending so much time improving the above issues, it would be a shame if we were working on unrelated changes and accidentally regressed our improvements!
To assist us in this, we built a lightweight performance test suite into the Boomerang build infrastructure that can be executed on-demand and the results can be compared to previous runs.
We built the performance tests on top of our existing End-to-End (E2E) tests, which are basic HTML pages we use to test Boomerang in various scenarios. Today we have over 550+ E2E tests that run on every build.
The new Boomerang Performance Tests utilize a similar test infrastructure and also track metrics built into the debug builds of Boomerang, such as the scenario’s CPU time or how many times the cookie was set.
Example results of running one Boomerang Test scenario:
> grunt perf
{
"00-basic": {
"00-empty": {
"page_load_time": 30,
"boomerang_javascript_time": 29.5,
"total_javascript_time": 43,
"mark_startup_called": 1,
"mark_check_doc_domain_called": 4,
...
}
If we re-run the same test later after making changes, we can directly compare the results:
> grunt perf:compare
Running "perf-compare" task
Results comparison to baseline:
00-basic.00-empty.page_load_time : 30 -6 (-20%)
We still need to be attentive to our changes and to run these test automatically to “hold the line”.
We also need to try to be mindful and put in instrumentation (metrics) when we’re making fixes to make sure we have something to track over time.
You can review our change here.
Next
With all of the above improvements, where are we at?
We’ve:
- Reduced the overhead and increased the compatibility of the Loader Snippet
- Reduced the CPU cost of gathering ResourceTiming data
- Reduced the size of Boomerang by stripping debug messages, applying smarter minification, and enabling Brotli
- Reduced the size of and overhead of cookies for Session tracking
- Reduced the size of Boomerang and complexity of hashing URLs by switching to FNV, and by simplifying our SPA plugins
- Created a Performance Test Suite to track our improvements over time
All of these changes had to be balanced against the other work we do to improve the library itself. We still have a large list of other performance-related items we hope to tackle in 2020.
One of the main areas we continue to focus on is Boomerang’s size. As more features, reliability and compatibility fixes get added, Boomerang continues to increase in size. While we’ve done a lot of work to keep it under 50 KB (over the wire), we know there is more we can do.
One thing we’re looking into for our mPulse customers is to deliver builds of Boomerang with the minimal features necessary for that application’s configuration. For example, if Single Page App support is not needed, all of the related SPA plugins can be omitted. We’re exploring ways of quickly switching between different builds of Boomerang for mPulse customers, while still having a high browser cache hit rate and yet allowing customers to change their configuration and see it “live” within 5 minutes.
Note that open-source users of Boomerang can always build a custom build with only the plugins they care about. Depending on the features needed, open-source builds can be under 30 KB with the majority of the plugins included.
Thanks
Boomerang is built by the developers at Akamai and the broader performance community on Github. Many people have a hand in building and improving Boomerang, including the changes mentioned above by: Nigel Heron, Nic Jansma, Andreas Marschke, Avinash Shenoy, Tsvetan Stoychev, Philip Tellis, Tim Vereecke, Aleksey Zemlyanskiy, and all of the other open-source contributors.